Metrics
Open Service Mesh (OSM) generates detailed metrics related to all traffic within the mesh and the OSM control plane. These metrics provide insights into the behavior of applications in the mesh and the mesh itself helping users to troubleshoot, maintain and analyze their applications.
OSM collects metrics directly from the sidecar proxies (Envoy). With these metrics the user can get information about the overall volume of traffic, errors within traffic and the response time for requests.
Additionally, OSM generates metrics for the control plane components. These metrics can be used to monitor the behavior and health of the service mesh.
OSM uses Prometheus to gather and store consistent traffic metrics and statistics for all applications running in the mesh. Prometheus is an open-source monitoring and alerting toolkit which is commonly used on (but not limited to) Kubernetes and Service Mesh environments.
Each application that is part of the mesh runs in a Pod which contains an Envoy sidecar that exposes metrics (proxy metrics) in the Prometheus format. Furthermore, every Pod that is a part of the mesh and in a namespace with metrics enabled has Prometheus annotations, which makes it possible for the Prometheus server to scrape the application dynamically. This mechanism automatically enables scraping of metrics whenever a pod is added to the mesh.
OSM metrics can be viewed with Grafana which is an open source visualization and analytics software. It allows you to query, visualize, alert on, and explore your metrics.
Grafana uses Prometheus as backend timeseries database. If Grafana and Prometheus are chosen to be deployed through OSM installation, necessary rules will be set upon deployment for them to interact. Conversely, on a “Bring-Your-Own” or “BYO” model (further explained below), installation of these components will be taken care of by the user.
Installing Metrics Components
OSM can either provision Prometheus and Grafana instances at install time or OSM can connect to an existing Prometheus and/or Grafana instance. We call the latter pattern “Bring-Your-Own” or “BYO”. The sections below describe how to configure metrics by allowing OSM to automatically provision the metrics components and with the BYO method.
Automatic Provisioning
By default, both Prometheus and Grafana are disabled.
However, when configured with the --set=osm.deployPrometheus=true flag, OSM installation will deploy a Prometheus instance to scrape the sidecar’s metrics endpoints. Based on the metrics scraping configuration set by the user, OSM will annotate pods part of the mesh with necessary metrics annotations to have Prometheus reach and scrape the pods to collect relevant metrics. The scraping configuration file defines the default Prometheus behavior and the set of metrics collected by OSM.
To install Grafana for metrics visualization, pass the --set=osm.deployGrafana=true flag to the osm install command. OSM provides a pre-configured dashboard that is documented in OSM Grafana dashboards.
osm install --set=osm.deployPrometheus=true \
--set=osm.deployGrafana=true
Note: The Prometheus and Grafana instances deployed automatically by OSM have simple configurations that do not include high availability, persistent storage, or locked down security. If production-grade instances are required, pre-provision them and follow the BYO instructions on this page to integrate them with OSM.
Bring-Your-Own
Prometheus
The following section documents the additional steps needed to allow an already running Prometheus instance to poll the endpoints of an OSM mesh.
List of Prerequisites for BYO Prometheus
- Already running an accessible Prometheus instance outside of the mesh.
- A running OSM control plane instance, deployed without metrics stack.
- We will assume having Grafana reach Prometheus, exposing or forwarding Prometheus or Grafana web ports and configuring Prometheus to reach Kubernetes API services is taken care of or otherwise out of the scope of these steps.
Configuration
- Make sure the Prometheus instance has appropriate RBAC rules to be able to reach both the pods and Kubernetes API - this might be dependent on specific requirements and situations for different deployments:
- apiGroups: [""]
resources: ["nodes", "nodes/proxy", "nodes/metrics", "services", "endpoints", "pods", "ingresses", "configmaps"]
verbs: ["list", "get", "watch"]
- apiGroups: ["extensions"]
resources: ["ingresses", "ingresses/status"]
verbs: ["list", "get", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
- If desired, use the Prometheus Service definition to allow Prometheus to scrape itself:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "<API port for prometheus>" # Depends on deployment - OSM automatic deployment uses 7070 by default, controlled by `values.yaml`
- Amend Prometheus’ configmap to reach the pods/Envoy endpoints. OSM automatically appends the port annotations to the pods and takes care of pushing the listener configuration to the pods for Prometheus to reach:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: source_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: source_pod_name
- regex: '(__meta_kubernetes_pod_label_app)'
action: labelmap
replacement: source_service
- regex: '(__meta_kubernetes_pod_label_osm_envoy_uid|__meta_kubernetes_pod_label_pod_template_hash|__meta_kubernetes_pod_label_version)'
action: drop
- source_labels: [__meta_kubernetes_pod_controller_kind]
action: replace
target_label: source_workload_kind
- source_labels: [__meta_kubernetes_pod_controller_name]
action: replace
target_label: source_workload_name
- source_labels: [__meta_kubernetes_pod_controller_kind]
action: replace
regex: ^ReplicaSet$
target_label: source_workload_kind
replacement: Deployment
- source_labels:
- __meta_kubernetes_pod_controller_kind
- __meta_kubernetes_pod_controller_name
action: replace
regex: ^ReplicaSet;(.*)-[^-]+$
target_label: source_workload_name
Grafana
The following section assumes a Prometheus instance has already been configured as a data source for a running Grafana instance. Refer to the Prometheus and Grafana demo for an example on how to create and configure a Grafana instance.
Importing OSM Dashboards
OSM Dashboards are available through our repository, which can be imported as json blobs on the web admin portal.
Detailed instructions for importing OSM dashboards can be found in the Prometheus and Grafana demo. Refer to OSM Grafana dashboard for an overview of the pre-configured dashboards.
Metrics scraping
Metrics scraping can be configured using the osm metrics command. By default, OSM does not configure metrics scraping for pods in the mesh. Metrics scraping can be enabled or disabled at namespace scope such that pods belonging to configured namespaces can be enabled or disabled for scraping metrics.
For metrics to be scraped, the following prerequisites must be met:
- The namespace must be a part of the mesh, ie. it must be labeled with the
openservicemesh.io/monitored-bylabel with an appropriate mesh name. This can be done using theosm namespace addcommand. - A running service able to scrape Prometheus endpoints. OSM provides configuration for an automatic bringup of Prometheus; alternatively users can bring their own Prometheus.
To enable one or more namespaces for metrics scraping:
osm metrics enable --namespace test
osm metrics enable --namespace "test1, test2"
To disable one or more namespaces for metrics scraping:
osm metrics disable --namespace test
osm metrics disable --namespace "test1, test2"
Enabling metrics scraping on a namespace also causes the osm-injector to add the following annotations to pods in that namespace:
prometheus.io/scrape: true
prometheus.io/port: 15010
prometheus.io/path: /stats/prometheus
Available Metrics
OSM exports metrics about the traffic within the mesh as well as metrics about the control plane.
Custom Envoy Metrics
Each Envoy proxy exposes metrics in the Prometheus format. For details about what metrics are exposed, see Envoy’s documentation. OSM’s default Prometheus configuration only scrapes a subset of all metrics generated by each proxy.
To implement the SMI metrics spec, OSM adds a custom WebAssembly extension to each Envoy proxy which generates the following statistics for HTTP traffic:
osm_request_total: A counter incremented for each request made by the proxy. This can be queried to determine success and failure rates of services in the mesh.
osm_request_duration_ms: A histogram representing the duration of requests made by the proxy in milliseconds. This can be queried to determine the latency between services in the mesh.
Both metrics have the following labels:
source_kind: The Kubernetes resource kind of the workload making the request, e.g. Deployment, DaemonSet, etc.
destination_kind: The Kubernetes resource kind of the workload handling the request, e.g. Deployment, DaemonSet, etc.
source_name: The Kubernetes name of the workload making the request.
destination_name: The Kubernetes name of the workload handling the request.
source_pod: The Kubernetes name of the pod making the request.
destination_pod: The Kubernetes name of the pod handling the request.
source_namespace: The Kubernetes namespace of the workload making the request.
destination_namespace: The Kubernetes namespace of the workload handling the request.
In addition, the osm_request_total metric has a response_code label representing the HTTP status code of each request, e.g. 200, 404, etc.
Known Gaps
- HTTP requests that invoke a local response from Envoy have “unknown”
destination_*labels on metrics.- In the demo, this includes requests from the bookthief to the bookstore.
- Metrics are only recorded for traffic where both endpoints are part of the mesh. Ingress and egress traffic do not have statistics recorded.
- Metrics are recorded in Prometheus with all instances of ‘-’ and ‘.’ in tags converted to ‘_’. This is because proxy-wasm adds tags to metrics through the name of the metric and Prometheus does not allow ‘-’ or ‘.’ in metric names, so Envoy converts them all to ‘_’ for the Prometheus format. This means a pod named ‘abc-123’ is labeled in Prometheus as ‘abc_123’ and metrics for pods ‘abc-123’ and ‘abc.123’ would be tracked as a single pod ‘abc_123’ and only distinguishable by the ‘instance’ label containing the pod’s IP address.
Control Plane
The following metrics are exposed in the Prometheus format by the OSM control plane components. The osm-controller and osm-injector pods have the following Prometheus annotation.
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9091'
| Metric | Type | Labels | Description |
|---|---|---|---|
| osm_k8s_api_event_count | Count | type, namespace | Number of events received from the Kubernetes API Server |
| osm_proxy_connect_count | Gauge | Number of proxies connected to OSM controller | |
| osm_proxy_reconnect_count | Count | IngressGateway defines the certificate specification for an ingress gateway | |
| osm_proxy_response_send_success_count | Count | common_name, type | Number of responses successfully sent to proxies |
| osm_proxy_response_send_error_count | Count | common_name, type | Number of responses that errored when being set to proxies |
| osm_proxy_config_update_time | Histogram | resource_type, success | Histogram to track time spent for proxy configuration |
| osm_proxy_broadcast_event_count | Count | Number of ProxyBroadcast events published by the OSM controller | |
| osm_proxy_xds_request_count | Count | common_name, type | Number of XDS requests made by proxies |
| osm_proxy_max_connections_rejected | Count | Number of proxy connections rejected due to the configured max connections limit | |
| osm_cert_issued_count | Count | Total number of XDS certificates issued to proxies | |
| osm_cert_issued_time | Histogram | Histogram to track time spent to issue xds certificate | |
| osm_admission_webhook_response_total | Count | kind, success | Total number of admission webhook responses generated |
| osm_error_err_code_count | Count | err_code | Number of errcodes generated by OSM |
| osm_http_response_total | Count | code, method, path | Number of HTTP responses sent |
| osm_http_response_duration | Histogram | code, method, path | Duration in seconds of HTTP responses sent |
| osm_feature_flag_enabled | Gauge | feature_flag | Represents whether a feature flag is enabled (1) or disabled (0) |
| osm_conversion_webhook_resource_total | Count | kind, success, from_version, to_version | Number of resources converted by conversion webhooks |
Error Code Metrics
When an error occurs in the OSM control plane the ErrCodeCounter Prometheus metric is incremented for the related OSM error code. For the complete list of error codes and their descriptions, see OSM Control Plane Error Code Troubleshooting Guide.
The fully-qualified name of the error code metric is osm_error_err_code_count.
Note: Metrics corresponding to errors that result in process restarts might not be scraped in time.
Query metrics from Prometheus
Before you begin
Ensure that you have followed the steps to run OSM Demo
Querying proxy metrics for request count
- Verify that the Prometheus service is running in your cluster
- In kubernetes, execute the following command:
kubectl get svc osm-prometheus -n <osm-namespace>.
- Note:
<osm-namespace>refers to the namespace where the osm control plane is installed.
- In kubernetes, execute the following command:
- Open up the Prometheus UI
- Ensure you are in root of the repository and execute the following script:
./scripts/port-forward-prometheus.sh - Visit the following url http://localhost:7070 in your web browser
- Ensure you are in root of the repository and execute the following script:
- Execute a Prometheus query
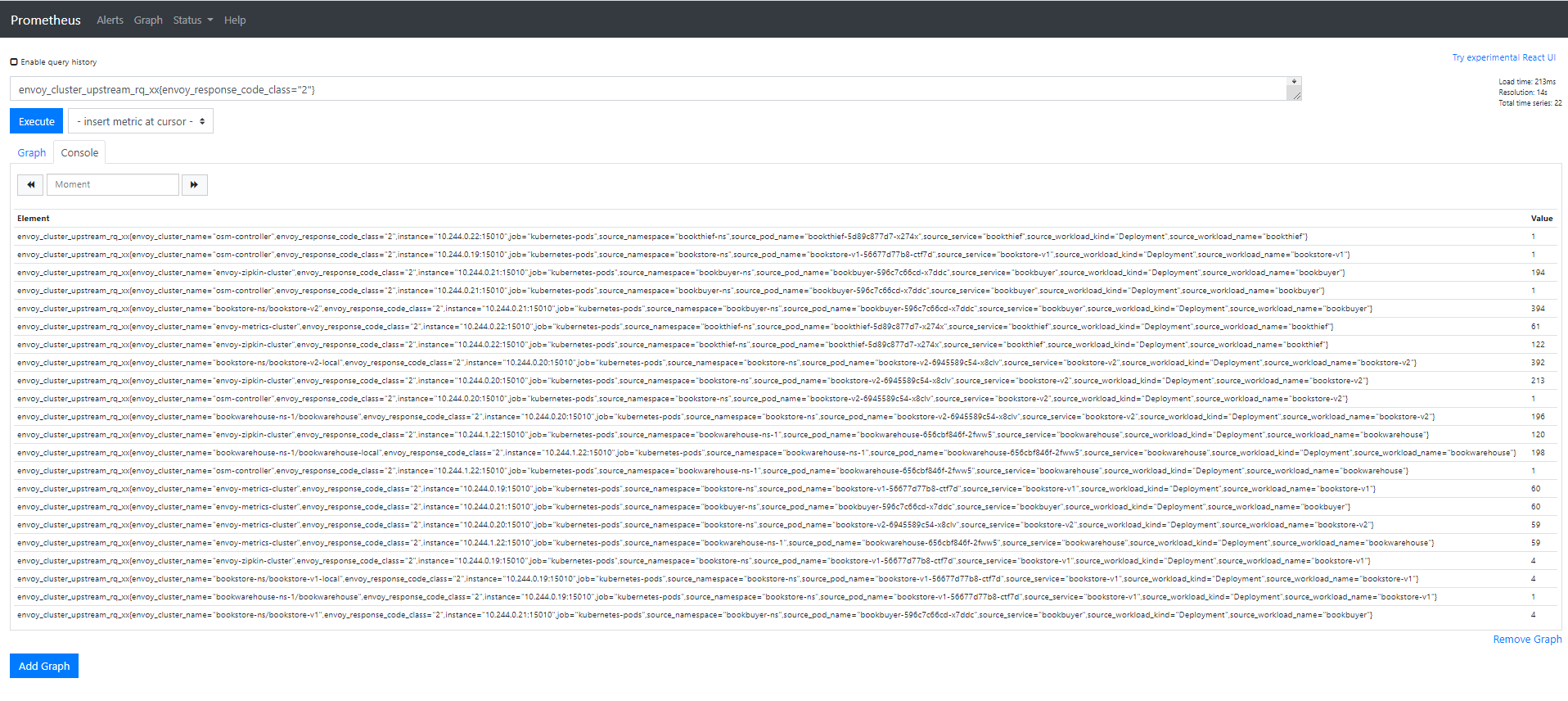
- In the “Expression” input box at the top of the web page, enter the text:
envoy_cluster_upstream_rq_xx{envoy_response_code_class="2"}and click the execute button - This query will return the successful http requests
- In the “Expression” input box at the top of the web page, enter the text:
Sample result will be:
Visualize metrics with Grafana
List of Prerequisites for Viewing Grafana Dashboards
Ensure that you have followed the steps to run OSM Demo
Viewing a Grafana dashboard for service to service metrics
- Verify that the Prometheus service is running in your cluster
- In kubernetes, execute the following command:
kubectl get svc osm-prometheus -n <osm-namespace>
- In kubernetes, execute the following command:
- Verify that the Grafana service is running in your cluster
- In kubernetes, execute the following command:
kubectl get svc osm-grafana -n <osm-namespace>
- In kubernetes, execute the following command:
- Open up the Grafana UI
- Ensure you are in root of the repository and execute the following script:
./scripts/port-forward-grafana.sh - Visit the following url http://localhost:3000 in your web browser
- Ensure you are in root of the repository and execute the following script:
- The Grafana UI will request for login details, use the following default settings:
- username: admin
- password: admin
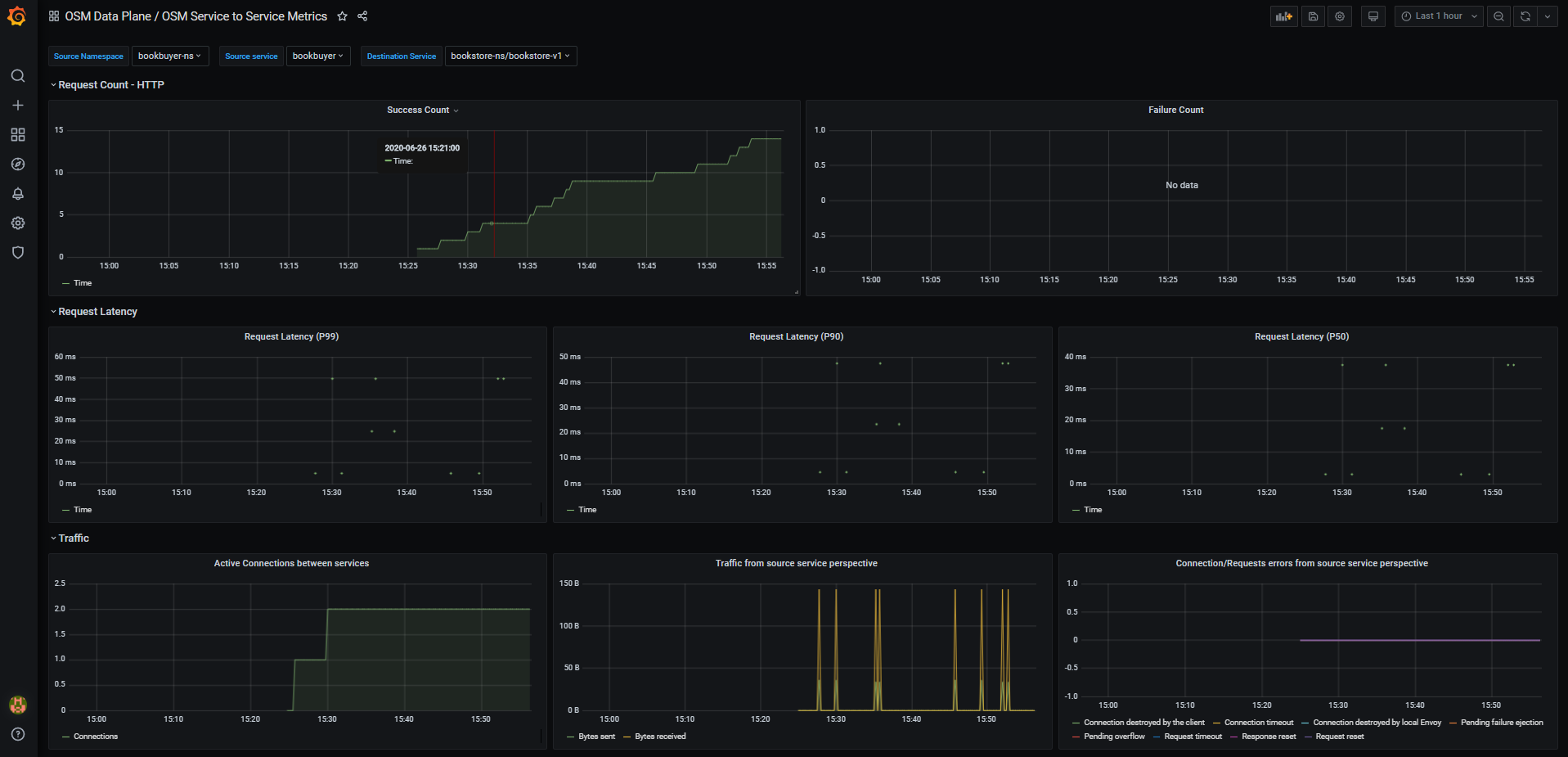
- Viewing Grafana dashboard for service to service metrics
- From the Grafana’s dashboards left hand corner navigation menu you can navigate to the OSM Service to Service Dashboard in the folder OSM Data Plane
- Or visit the following url http://localhost:3000/d/OSMs2sMetrics/osm-service-to-service-metrics?orgId=1 in your web browser
OSM Service to Service Metrics dashboard will look like:
OSM Grafana dashboards
OSM provides some pre-cooked Grafana dashboards to display and track services related information captured by Prometheus:
-
OSM Data Plane
- OSM Data Plane Performance Metrics: This dashboard lets you view the performance of OSM’s data plane

- OSM Service to Service Metrics: This dashboard lets you view the traffic metrics from a given source service to a given destination service

- OSM Pod to Service Metrics: This dashboard lets you investigate the traffic metrics from a pod to all the services it connects/talks to

- OSM Workload to Service Metrics: This dashboard provides the traffic metrics from a workload (deployment, replicaSet) to all the services it connects/talks to

- OSM Workload to Workload Metrics: This dashboard displays the latencies of requests in the mesh from workload to workload

- OSM Data Plane Performance Metrics: This dashboard lets you view the performance of OSM’s data plane
-
OSM Control Plane
- OSM Control Plane Metrics: This dashboard provides traffic metrics from the given service to OSM’s control plane

- Mesh and Envoy Details: This dashboard lets you view the performance and behavior of OSM’s control plane

- OSM Control Plane Metrics: This dashboard provides traffic metrics from the given service to OSM’s control plane
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.